
在k8s中运行 netshoot 进行抓包
busybox 虽然很小,但是命令不全,可以使用 netshoot 来抓包,或者 praqma/network-multitool
补充一张 netshoot 的图:
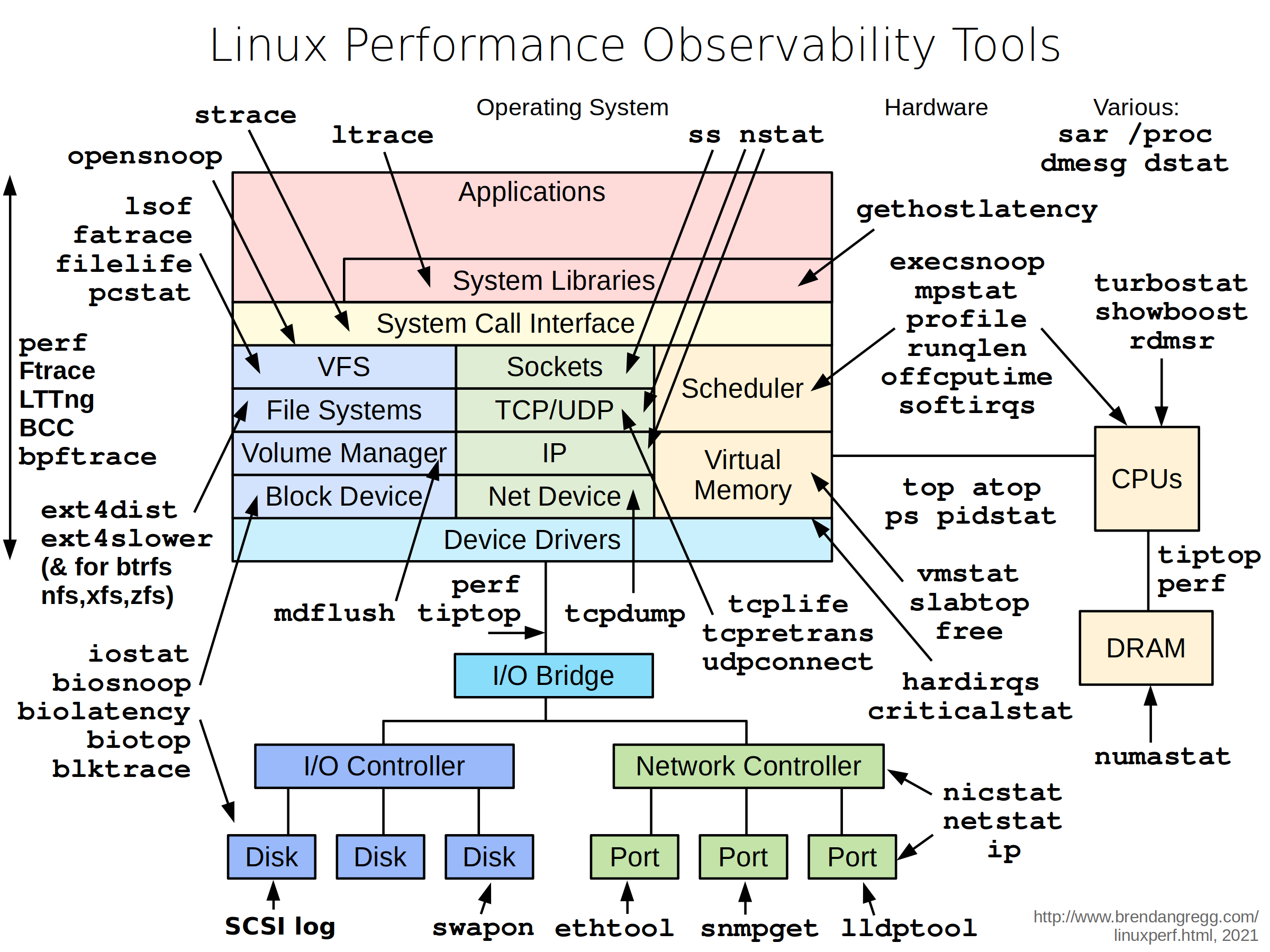
启动一个临时容器,可以调试整个容器网络
kubectl run --generator=run-pod/v1 tmp-shell --rm -i --tty --image nicolaka/netshoot -- /bin/bash
再开一个 shell: kubectl exec -it tmp-shell -- /bin/bash
或者启动一个临时容器,调试主机网络
kubectl run tmp-shell --generator=run-pod/v1 --rm -i --tty --overrides='{"spec": {"hostNetwork": true}}' --image nicolaka/netshoot -- /bin/bash
执行 tcpdump -nn -i any,再另外一个 shell 中,ping 一个可解析的地址,抓包结果如下
bash-5.1# tcpdump -nn -i any
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
05:52:58.482205 eth0 Out IP 10.244.21.244.60478 > 172.16.0.10.53: 32600+ A? eos.h3c.com.default.svc.cluster.local. (55)
05:52:58.482390 eth0 Out IP 10.244.21.244.60478 > 172.16.0.10.53: 32818+ AAAA? eos.h3c.com.default.svc.cluster.local. (55)
05:52:58.483641 eth0 In IP 172.16.0.10.53 > 10.244.21.244.60478: 32600 NXDomain*- 0/1/0 (148)
05:52:58.483657 eth0 In IP 172.16.0.10.53 > 10.244.21.244.60478: 32818 NXDomain*- 0/1/0 (148)
05:52:58.483696 eth0 Out IP 10.244.21.244.48575 > 172.16.0.10.53: 28447+ A? eos.h3c.com.svc.cluster.local. (47)
05:52:58.483797 eth0 Out IP 10.244.21.244.48575 > 172.16.0.10.53: 28617+ AAAA? eos.h3c.com.svc.cluster.local. (47)
05:52:58.485032 eth0 In IP 172.16.0.10.53 > 10.244.21.244.48575: 28447 NXDomain*- 0/1/0 (140)
05:52:58.485044 eth0 In IP 172.16.0.10.53 > 10.244.21.244.48575: 28617 NXDomain*- 0/1/0 (140)
05:52:58.485078 eth0 Out IP 10.244.21.244.45182 > 172.16.0.10.53: 42126+ A? eos.h3c.com.cluster.local. (43)
05:52:58.485144 eth0 Out IP 10.244.21.244.45182 > 172.16.0.10.53: 42288+ AAAA? eos.h3c.com.cluster.local. (43)
05:52:58.485946 eth0 In IP 172.16.0.10.53 > 10.244.21.244.45182: 42288 NXDomain*- 0/1/0 (136)
05:52:58.486019 eth0 In IP 172.16.0.10.53 > 10.244.21.244.45182: 42126 NXDomain*- 0/1/0 (136)
05:52:58.486055 eth0 Out IP 10.244.21.244.58772 > 172.16.0.10.53: 34146+ A? eos.h3c.com. (29)
05:52:58.486119 eth0 Out IP 10.244.21.244.58772 > 172.16.0.10.53: 34350+ AAAA? eos.h3c.com. (29)
05:52:58.488728 eth0 In IP 172.16.0.10.53 > 10.244.21.244.58772: 34146* 1/0/0 A 10.64.252.13 (56)
05:52:58.488744 eth0 In IP 172.16.0.10.53 > 10.244.21.244.58772: 34350* 0/1/0 (99)
05:52:58.489020 eth0 Out IP 10.244.21.244 > 10.64.252.13: ICMP echo request, id 38727, seq 1, length 64
05:52:58.490880 eth0 In IP 10.64.252.13 > 10.244.21.244: ICMP echo reply, id 38727, seq 1, length 64
05:52:58.490951 eth0 Out IP 10.244.21.244.51005 > 172.16.0.10.53: 2157+ PTR? 13.252.64.10.in-addr.arpa. (43)
05:52:58.493904 eth0 In IP 172.16.0.10.53 > 10.244.21.244.51005: 2157 NXDomain* 0/1/0 (121)
05:53:03.487789 eth0 In ARP, Request who-has 10.244.21.244 tell 10.244.21.1, length 28
05:53:03.487792 eth0 Out ARP, Request who-has 10.244.21.1 tell 10.244.21.244, length 28
05:53:03.487797 eth0 Out ARP, Reply 10.244.21.244 is-at 82:ba:03:94:44:9b, length 28
05:53:03.487811 eth0 In ARP, Reply 10.244.21.1 is-at b2:b1:f0:a6:cd:fb, length 28
首先,系统尝试通过 DNS 解析 eos.h3c.com 的 IP 地址。它向 DNS 服务器(IP 地址为 172.16.0.10,端口 53)发送了一系列的 DNS 查询请求,尝试解析 eos.h3c.com 在不同的 Kubernetes 域中的地址。这些查询包括:
eos.h3c.com.default.svc.cluster.local
eos.h3c.com.svc.cluster.local
eos.h3c.com.cluster.local
eos.h3c.com
对于每个查询,系统都发送了两个请求:一个是 A 记录(IPv4 地址),另一个是 AAAA 记录(IPv6 地址)。
DNS 服务器回复了这些查询,大部分查询返回了 NXDomain(表示域名不存在)。但是,对于 eos.h3c.com 的查询,DNS 服务器返回了一个 A 记录,IP 地址为 10.64.252.13。
接下来,系统使用 ICMP 协议向 IP 地址 10.64.252.13 发送了一个 echo 请求(ping 请求)。这是一个用于测试网络连通性的标准操作。
IP 地址 10.64.252.13 回复了一个 ICMP echo 回复(ping 回复),表示网络连通性良好。
然后,系统尝试通过反向 DNS 解析(PTR 记录)查询 IP 地址 10.64.252.13 的主机名。DNS 服务器返回了 NXDomain,表示没有找到与该 IP 地址关联的主机名。
最后,系统与网关(IP 地址为 10.244.21.1)进行了 ARP 通信,以获取网关的 MAC 地址。这是一个正常的网络操作,用于在本地网络中找到目标设备的物理地址。
补充:
1 中测试了很多域名地址,这和搜索域配置有关系。
5 可能不是很理解,RTP 是一种通过 ip 反向查询主机名的解析,我们平时执行很多网络分析命令,可以选择是否显示主机名,就是 RTP 通过反查记录的。
6 最后 ARP 获取 MAC 地址
5,6 不一定是必须的,看你网络设置
通过容器 Network Namespace 抓包
查看指定 pod 运行在哪个宿主机上:
kubctl describe pod <pod> -n mservice获得容器的 pid:
docker inspect -f {{.State.Pid}} <container>进入该容器的 network namespace:
nsenter --target <PID> -n使用宿主机的
tcpdump抓包, 指定 eth0 网卡:tcpdump -i eth0 tcp and port 80 -vvv或者直接抓包并导出到文件:
tcpdump -i eth0 -w /tmp/out.cap从远程
scp到本地:scp ipaddr:/tmp/out.cap ./之后在 Wireshark 中可以打开文件非常直观的查看过滤抓到的数据
k8s DNS 解析过多导致请求慢问题
发现应用程序,如果请求集群外的地址,出现非常慢的情况,就是要等一个 2,3 秒,很多使用域名做 rpc 地址的服务都遇到了这个问题,改成 svc 内部地址就好了,难道是网关太慢?2,3 秒可不是慢的问题了,今天通过抓包来详细分析这个问题
这个是 dns resolve.conf 配置的问题,pod 可以设置 dns 策略,一般是 dnsPolicy: ClusterFirst
找一个容器,以下是 pod 内的 resolve.conf 配置:
root@/# cat /etc/resolv.conf
nameserver 172.16.0.10
search eos-system.svc.cluster.local svc.cluster.local cluster.local search h3c.com huawei-3com.com
options ndots:5nameserver 指定 dns 解析服务器(nameserver 表示解析域名时使用该地址指定的主机为域名服务器。其中域名服务器是按照文件中出现的顺序来查询的,且只有当第一个 nameserver 没有反应时才查询下面的 nameserver,一般不要指定超过 3 个服务器)
search 是搜索域
option 是配置项,这里配置了 ndots 5
因为 k8s 默认 ndots 5,所以会生成 3 个搜索域 eos-system.svc.cluster.local svc.cluster.local cluster.local,然后从主机拿 2 个 h3c.com huawei-3com.com
此时主机的 cat /etc/resolv.conf 配置为:
search h3c.com huawei-3com.com h3c.huawei-3com.com srv.huawei-3com.com ipa-h3c.com
nameserver 10.72.66.37
nameserver 10.72.66.36如果我们注释了 search:
#search h3c.com huawei-3com.com h3c.huawei-3com.com srv.huawei-3com.com ipa-h3c.com
nameserver 10.72.66.37
nameserver 10.72.66.36
那么容器内部为:
nameserver 172.16.0.10
search eos-system.svc.cluster.local svc.cluster.local cluster.local
options ndots:5回到正题,现在搜索域如下:
search eos-mid-public.svc.cluster.local svc.cluster.local cluster.local search h3c.com huawei-3com.com
在这个配置下,如果我们请求非 k8s 内部地址,就会拼接这样的地址去解析 dns 地址
eos.h3c.com.eos-system.svc.cluster.localeos.h3c.com.svc.cluster.localeos.h3c.com.cluster.localeos.h3c.com.h3c.comeos.h3c.com.huawei-3com.comeos.h3c.com
到第六次,终于拿到解析地址了,大家可以抓包验证一下
例子:
给业务容器,加一个 netshoot,进入到 netshoot 中执行抓包: kubectl -n eos-mid-public exec -it data-ease-v1-6b68dc7599-9rwm5 -c netshoot -- sh
Search Line limits were exceeded 错误事件
Search Line limits were exceeded, some search paths have been omitted, the applied search line is: eos-system.svc.cluster.local svc.cluster.local cluster.local search h3c.com huawei-3com.com
你会在 pod 事件在看到这个异常,主要还是搜索域配置问题,下面是比较官方一点的解答:
在/etc/resolv.conf文件中,search关键字用于指定一系列的搜索域,这些域会被用于 DNS 解析没有指定完全限定域名(FQDN)的主机名。如果文件中有多个search行,通常只有最后一个search行会被使用。
在这个例子中,有两个search关键字,每个关键字后面都跟着一些域名。这种写法在语法上是合法的,但实际上,只有最后一个search行(即search h3c.com huawei-3com.com h3c.huawei-3com.com srv.huawei-3com.com ipa-h3c.com)会被使用。
然而,看到的警告信息表明,搜索路径的长度超过了限制,因此一些搜索路径被省略了。这个限制是由 Linux 系统的 DNS 解析器强制的,搜索路径的总长度(包括所有的域名和空格)不能超过 256 个字符,搜索路径中的域名数量不能超过 6 个。
在这个例子中,搜索路径的长度可能超过了这个限制,因此 Kubernetes 只保留了前几个域名,并显示了这个警告信息。被省略的域名将不会被用于 DNS 解析。
如果需要使用被省略的域名进行 DNS 解析,可能需要调整搜索路径,使其长度不超过限制。例如,可以移除一些不需要的域名,或者将一些域名缩短。请注意,这可能需要修改 Kubernetes 的 DNS 配置,或者在创建 Pod 时指定自定义的 DNS 策略。
也就是说搜索域太长了,主要还是主机的配置加上 k8s 自身的配置导致的。另外通过抓包,发现 2 个 search 也是有作用的:
tcpdump -nn -i any host 172.16.0.10
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
07:27:48.006823 eth0 Out IP 10.244.38.246.52863 > 172.16.0.10.53: 39793+ A? eos.h3c.com.eos-mid-public.svc.cluster.local. (62)
07:27:48.007042 eth0 Out IP 10.244.38.246.52863 > 172.16.0.10.53: 40184+ AAAA? eos.h3c.com.eos-mid-public.svc.cluster.local. (62)
07:27:48.008818 eth0 In IP 172.16.0.10.53 > 10.244.38.246.52863: 40184 NXDomain*- 0/1/0 (155)
07:27:48.008830 eth0 In IP 172.16.0.10.53 > 10.244.38.246.52863: 39793 NXDomain*- 0/1/0 (155)
07:27:48.008867 eth0 Out IP 10.244.38.246.38655 > 172.16.0.10.53: 5074+ A? eos.h3c.com.svc.cluster.local. (47)
07:27:48.009010 eth0 Out IP 10.244.38.246.38655 > 172.16.0.10.53: 5321+ AAAA? eos.h3c.com.svc.cluster.local. (47)
07:27:48.009886 eth0 In IP 172.16.0.10.53 > 10.244.38.246.38655: 5321 NXDomain*- 0/1/0 (140)
07:27:48.009892 eth0 In IP 172.16.0.10.53 > 10.244.38.246.38655: 5074 NXDomain*- 0/1/0 (140)
07:27:48.009929 eth0 Out IP 10.244.38.246.49129 > 172.16.0.10.53: 19272+ A? eos.h3c.com.cluster.local. (43)
07:27:48.009994 eth0 Out IP 10.244.38.246.49129 > 172.16.0.10.53: 19552+ AAAA? eos.h3c.com.cluster.local. (43)
07:27:48.010661 eth0 In IP 172.16.0.10.53 > 10.244.38.246.49129: 19552 NXDomain*- 0/1/0 (136)
07:27:48.010688 eth0 In IP 172.16.0.10.53 > 10.244.38.246.49129: 19272 NXDomain*- 0/1/0 (136)
07:27:48.010719 eth0 Out IP 10.244.38.246.58992 > 172.16.0.10.53: 25097+ A? eos.h3c.com.search. (36)
07:27:48.010780 eth0 Out IP 10.244.38.246.58992 > 172.16.0.10.53: 25300+ AAAA? eos.h3c.com.search. (36)
07:27:50.014100 eth0 In IP 172.16.0.10.53 > 10.244.38.246.58992: 25300 NXDomain 0/1/0 (143)
07:27:50.014143 eth0 In IP 172.16.0.10.53 > 10.244.38.246.58992: 25097 NXDomain 0/1/0 (143)
07:27:50.014200 eth0 Out IP 10.244.38.246.33191 > 172.16.0.10.53: 7012+ A? eos.h3c.com.h3c.com. (37)
07:27:50.014425 eth0 Out IP 10.244.38.246.33191 > 172.16.0.10.53: 7264+ AAAA? eos.h3c.com.h3c.com. (37)
07:27:50.018603 eth0 In IP 172.16.0.10.53 > 10.244.38.246.33191: 7012 NXDomain* 0/1/0 (107)
07:27:50.018619 eth0 In IP 172.16.0.10.53 > 10.244.38.246.33191: 7264 NXDomain* 0/1/0 (107)
07:27:50.018666 eth0 Out IP 10.244.38.246.58819 > 172.16.0.10.53: 34729+ A? eos.h3c.com.huawei-3com.com. (45)
07:27:50.018755 eth0 Out IP 10.244.38.246.58819 > 172.16.0.10.53: 34926+ AAAA? eos.h3c.com.huawei-3com.com. (45)
07:27:50.020462 eth0 In IP 172.16.0.10.53 > 10.244.38.246.58819: 34729 NXDomain* 0/1/0 (147)
07:27:50.021529 eth0 In IP 172.16.0.10.53 > 10.244.38.246.58819: 34926 NXDomain* 0/1/0 (147)
07:27:50.021571 eth0 Out IP 10.244.38.246.52231 > 172.16.0.10.53: 60607+ A? eos.h3c.com. (29)
07:27:50.021644 eth0 Out IP 10.244.38.246.52231 > 172.16.0.10.53: 60831+ AAAA? eos.h3c.com. (29)
07:27:50.023140 eth0 In IP 172.16.0.10.53 > 10.244.38.246.52231: 60831* 0/1/0 (99)
07:27:50.024305 eth0 In IP 172.16.0.10.53 > 10.244.38.246.52231: 60607* 1/0/0 A 10.64.252.13 (56)其实这个影响特别大,在多次 ping 测试中,至少要等待 2 到 3 秒以后,才开始响应 ICMP 请求,时间都花在解析域名上了
把刚才那个 pod,启动 2 个实例,然后另外一个实例,注释了主机的搜索域,现在的搜索域配置为
search eos-mid-public.svc.cluster.local svc.cluster.local cluster.local
再次抓包,并且测试 ping,发现很快就响应 ICMP 了,因为少了 h3c.com huawei-3com.com ,这 2 个不是集群内部的,之前的 2 到 3 秒的耗时就是因为拼接解析地址,然后耗时在这 2 个上
~ # tcpdump -nn -i any host 172.16.0.10
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
07:32:45.904074 eth0 Out IP 10.244.9.4.37992 > 172.16.0.10.53: 61923+ A? eos.h3c.com.eos-mid-public.svc.cluster.local. (62)
07:32:45.904448 eth0 Out IP 10.244.9.4.37992 > 172.16.0.10.53: 62647+ AAAA? eos.h3c.com.eos-mid-public.svc.cluster.local. (62)
07:32:45.906207 eth0 In IP 172.16.0.10.53 > 10.244.9.4.37992: 62647 NXDomain*- 0/1/0 (155)
07:32:45.906213 eth0 In IP 172.16.0.10.53 > 10.244.9.4.37992: 61923 NXDomain*- 0/1/0 (155)
07:32:45.906318 eth0 Out IP 10.244.9.4.44893 > 172.16.0.10.53: 491+ A? eos.h3c.com.svc.cluster.local. (47)
07:32:45.906475 eth0 Out IP 10.244.9.4.44893 > 172.16.0.10.53: 854+ AAAA? eos.h3c.com.svc.cluster.local. (47)
07:32:45.908170 eth0 In IP 172.16.0.10.53 > 10.244.9.4.44893: 854 NXDomain*- 0/1/0 (140)
07:32:45.908177 eth0 In IP 172.16.0.10.53 > 10.244.9.4.44893: 491 NXDomain*- 0/1/0 (140)
07:32:45.908284 eth0 Out IP 10.244.9.4.33141 > 172.16.0.10.53: 64130+ A? eos.h3c.com.cluster.local. (43)
07:32:45.908483 eth0 Out IP 10.244.9.4.33141 > 172.16.0.10.53: 64592+ AAAA? eos.h3c.com.cluster.local. (43)
07:32:45.909628 eth0 In IP 172.16.0.10.53 > 10.244.9.4.33141: 64592 NXDomain*- 0/1/0 (136)
07:32:45.909634 eth0 In IP 172.16.0.10.53 > 10.244.9.4.33141: 64130 NXDomain*- 0/1/0 (136)
07:32:45.909717 eth0 Out IP 10.244.9.4.58102 > 172.16.0.10.53: 62819+ A? eos.h3c.com. (29)
07:32:45.909894 eth0 Out IP 10.244.9.4.58102 > 172.16.0.10.53: 63062+ AAAA? eos.h3c.com. (29)
07:32:45.913220 eth0 In IP 172.16.0.10.53 > 10.244.9.4.58102: 63062* 0/1/0 (99)
07:32:45.913460 eth0 In IP 172.16.0.10.53 > 10.244.9.4.58102: 62819* 1/0/0 A 10.64.252.13 (56)
如果是请求集群内部地址呢?ping 一个 eos-project-blue.eos-system
~ # tcpdump -nn -i any host 172.16.0.10
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
07:40:13.472584 eth0 Out IP 10.244.9.4.59303 > 172.16.0.10.53: 23490+ A? eos-project-blue.eos-system.eos-mid-public.svc.cluster.local. (78)
07:40:13.472962 eth0 Out IP 10.244.9.4.59303 > 172.16.0.10.53: 24048+ AAAA? eos-project-blue.eos-system.eos-mid-public.svc.cluster.local. (78)
07:40:13.474561 eth0 In IP 172.16.0.10.53 > 10.244.9.4.59303: 23490 NXDomain*- 0/1/0 (171)
07:40:13.474614 eth0 In IP 172.16.0.10.53 > 10.244.9.4.59303: 24048 NXDomain*- 0/1/0 (171)
07:40:13.474666 eth0 Out IP 10.244.9.4.46662 > 172.16.0.10.53: 35395+ A? eos-project-blue.eos-system.svc.cluster.local. (63)
07:40:13.475014 eth0 Out IP 10.244.9.4.46662 > 172.16.0.10.53: 35807+ AAAA? eos-project-blue.eos-system.svc.cluster.local. (63)
07:40:13.476326 eth0 In IP 172.16.0.10.53 > 10.244.9.4.46662: 35807*- 0/1/0 (156)
07:40:13.476331 eth0 In IP 172.16.0.10.53 > 10.244.9.4.46662: 35395*- 1/0/0 A 172.16.162.110 (124)
由于 svc 不响应 ICMP 协议,但是不影响我们测试域名解析,抓包中看到第二次就解析到了
如何解决?
我们搞懂了这个问题的原理,知道是因为主机配置了搜索域,那么根据自己集群网络情况来,这里我们用一个比较简单的办法,调整搜索次数,在 yaml 中,指定 dns 配置
spec:
dnsConfig:
options:
- name: ndots
value: "2"发布后,新的容器已经启动,配置也变化了,虽然搜索域还是 5 个,但是 ndots:2 调整了
~ # cat /etc/resolv.conf
nameserver 172.16.0.10
search eos-mid-public.svc.cluster.local svc.cluster.local cluster.local search h3c.com huawei-3com.com
options ndots:2再次请求抓包,测试了 ping 集群外,和集群内
~ # tcpdump -nn -i any host 172.16.0.10
tcpdump: data link type LINUX_SLL2
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes
08:04:19.628042 eth0 Out IP 10.244.38.247.38433 > 172.16.0.10.53: 49804+ A? eos.h3c.com. (29)
08:04:19.628242 eth0 Out IP 10.244.38.247.38433 > 172.16.0.10.53: 50094+ AAAA? eos.h3c.com. (29)
08:04:19.629431 eth0 In IP 172.16.0.10.53 > 10.244.38.247.38433: 49804* 1/0/0 A 10.64.252.13 (56)
08:04:19.629443 eth0 In IP 172.16.0.10.53 > 10.244.38.247.38433: 50094* 0/1/0 (99)
08:04:19.631592 eth0 Out IP 10.244.38.247.54515 > 172.16.0.10.53: 3396+ PTR? 13.252.64.10.in-addr.arpa. (43)
08:04:19.634487 eth0 In IP 172.16.0.10.53 > 10.244.38.247.54515: 3396 NXDomain* 0/1/0 (121)
08:04:43.561728 eth0 Out IP 10.244.38.247.33567 > 172.16.0.10.53: 60025+ A? eos-project-blue.eos-system.eos-mid-public.svc.cluster.local. (78)
08:04:43.561911 eth0 Out IP 10.244.38.247.33567 > 172.16.0.10.53: 60442+ AAAA? eos-project-blue.eos-system.eos-mid-public.svc.cluster.local. (78)
08:04:43.564030 eth0 In IP 172.16.0.10.53 > 10.244.38.247.33567: 60442 NXDomain*- 0/1/0 (171)
08:04:43.564045 eth0 In IP 172.16.0.10.53 > 10.244.38.247.33567: 60025 NXDomain*- 0/1/0 (171)
08:04:43.564096 eth0 Out IP 10.244.38.247.50751 > 172.16.0.10.53: 16478+ A? eos-project-blue.eos-system.svc.cluster.local. (63)
08:04:43.564181 eth0 Out IP 10.244.38.247.50751 > 172.16.0.10.53: 16886+ AAAA? eos-project-blue.eos-system.svc.cluster.local. (63)
08:04:43.564904 eth0 In IP 172.16.0.10.53 > 10.244.38.247.50751: 16886*- 0/1/0 (156)
08:04:43.564913 eth0 In IP 172.16.0.10.53 > 10.244.38.247.50751: 16478*- 1/0/0 A 172.16.162.110 (124)发现集群外的,直接返回了,这里要特别注意 ndots:2 不是说在搜索域中拼接 2 次的意思。
在进行域名的 DNS 解析时,操作系统先判断其是否是一个 FQDN(Fully qualified domain name,即完整域名,指以 . 结尾的),如果是,则会直接查询 DNS 服务器;如果不是,则就要根据 search 和 ndots 的设置进行 FQDN 的拼接再将其发到 DNS 服务器进行解析。
ndots 表示的是完整域名中必须出现的 . 的个数,如果域名中的 . 的个数不小于 ndots,则该域名会被认为是一个 FQDN,操作系统会直接将其发给 DNS 服务器进行查询;否则,操作系统会在 search 搜索域中依次查询。
例如上面的例子,ndots 为 5,查询的域名 eos.h3c.com 不以 . 结尾,且 . 的个数少于 5,因此操作系统会依次在 default.svc.cluster.local svc.cluster.local cluster.local 三个域中进行搜索,这 3 个搜索域都是由 Kubernetes 注入的。
所以情况就是:
eos-project-blue.eos-system < ndots:2 在搜索域中找,第二个找到
eos.h3c.com > ndots:2,直接请求 eos.h3c.com,不再去搜索域中拼接地址
Kubernetes 为什么要使用搜索域?
目的是为了使 Pod 可以解析内部域名,比如通过 Service name 访问 Service。
例如 default namespace 下的 Pod a 需要访问同 namespace 中的 Service service-b 时,直接使用 service-b 就可以访问了,这就是通过在 default.svc.cluster.local 搜索域中搜索完成的。同理 svc.cluster.local 支持了对不同 namespace 下的 Service 访问,如 service-c.sre(意为 sre namespace 下的 service-c)。
Kubernetes 默认配置下 ndots 的值是 5,其原因官方在 issue 33554 中做了解释:
Kubernetes 需要一个标志来识别集群内的域名,因此 svc 是必须包含在域名内的。
有些人需要配置集群 $zone 的后缀以支持多集群,所以一个完整的 Service 的域名为 $service.$namespace.svc.$zone,为了不在代码中配置完整的域名,就需要设置 ndots 和 search。
同 namespace 下的 Service 的请求是最常用的,因此需要解析 $service,此时需 ndots >= 1,且 search 列表中第一个应为 $namespace.D.$zone。
跨 namespace 的 Service 也经常会被请求,因此需要解析 $service.$namespace,此时需 ndots >= 2,且 search 列表中第二个应为 svc.$zone。
为了解析 $service.$namespace.svc,此时需 ndots >= 3,且 search 列表包含 $zone。
在 Kubernetes 1.4 之前,StatefulSet 为 PetSet,当每个 Pet 被创建时,它会获得一个匹配的 DNS 子域,域格式为 $petname.$service.$namespace.svc.$zone,此时需 ndots >= 4。
Kubernetes 还支持 SRV 记录,因此 _$port.$proto.$service.$namespace.svc.$zone 需要可以解析,此时 ndots = 5。
这就是为什么 ndots 为 5。总结来说是为了支持更复杂的 Pod 内的域名解析,但通常情况下群脉只会用到同 namespace 下的 Service(形如 service-b)和跨 namespace 下 Service(形如 service-c.sre)的访问,因此 ndots 的默认值设为 2 便可满足业务需求并避免大量无效的解析请求。
或者调整配置,之前我们是因为 2 个不在集群内的地址,解析耗时,可以快速失败,或者修改主机搜索域(一般业务都用不到这个功能,可以改主机搜索域)
options 其他选项的补充说明
timeout:设置等待 DNS 服务器返回的超时时间,默认为 5,单位为秒。这个有点高了,为了 fail fast,我们设为了 2。
attempt:解析失败时的重试次数,默认为 2。为了提高成功率,我们设为了 3。
single-request:默认情况下会并行执行 IPv4 and IPv6 的解析,但某些 DNS 服务器可能无法正确处理这些查询使请求超时。该选项可以禁用此行为,并依次执行 IPv6 and IPv4 的解析。
rotate:采用轮询方式访问 nameserver。
no-check-names:禁止对传入的主机名和邮件地址进行无效字符检查。
use-vc:强制使用 TCP 进行 DNS 解析。
Kubernetes DNS 策略
None
表示空的 DNS 设置
这种方式一般用于想要自定义 DNS 配置的场景,而且,往往需要和 dnsConfig 配合一起使用达到自定义 DNS 的目的。
Default
有人说 Default 的方式,是使用宿主机的方式,这种说法并不准确。
这种方式,其实是,让 kubelet 来决定使用何种 DNS 策略。而 kubelet 默认的方式,就是使用宿主机的 /etc/resolv.conf(可能这就是有人说使用宿主机的 DNS 策略的方式吧),但是,kubelet 是可以灵活来配置使用什么文件来进行 DNS 策略的,我们完全可以使用 kubelet 的参数:–resolv-conf=/etc/resolv.conf 来决定你的 DNS 解析文件地址。
ClusterFirst
这种方式,表示 POD 内的 DNS 使用集群中配置的 DNS 服务,简单来说,就是使用 Kubernetes 中 kubedns 或 coredns 服务进行域名解析。如果解析不成功,才会使用宿主机的 DNS 配置进行解析。
ClusterFirstWithHostNet
在某些场景下,我们的 POD 是用 HOST 模式启动的(HOST 模式,是共享宿主机网络的),一旦用 HOST 模式,表示这个 POD 中的所有容器,都要使用宿主机的 /etc/resolv.conf 配置进行 DNS 查询,但如果你想使用了 HOST 模式,还继续使用 Kubernetes 的 DNS 服务,那就将 dnsPolicy 设置为 ClusterFirstWithHostNet。
参考资料:
Kubernetes Pod DNS 解析优化 - 知乎 (zhihu.com)
coredns 原理
域名服务器,本质就是一个 key-value 记录,在上面的分析中,外部地址在 k8s 内访问是能解析的,从抓包来看,都是请求到了 coredns。
k8s 默认 pod 的 dns 策略是 ClusterFirst,也就是指向 coredns 的 svc 地址,全部的域名解析请求都交给 coredns,而 coredns 的 dns 策略是 Default,意思是从所在 Node 继承 DNS 服务器,对于无法解析的外部域名,kube-dns 会继续向集群外部的 dns 进行查询,kube-dns 只能解析集群内部地址,而集群外部地址应该发给外部 DNS 服务器进行解析。
所以 k8s 能否解析外网,一般看 coredns 主机的配置,或者我们修改一个指定配置,另外在 coredns 的 configmap 中,还可以添加自定义解析记录,可以根据实际情况,灵活配置
kubectl 插件 sniff 抓包
sniff 是一个集成 tcpdump 等工具的抓包插件,安装它,首先要先安装 krew,一个类似 brew 的包管理工具
(
set -x; cd "$(mktemp -d)" &&
OS="$(uname | tr '[:upper:]' '[:lower:]')" &&
ARCH="$(uname -m | sed -e 's/x86_64/amd64/' -e 's/\(arm\)\(64\)\?.*/\1\2/' -e 's/aarch64$/arm64/')" &&
KREW="krew-${OS}_${ARCH}" &&
curl -fsSLO "http://github.com/kubernetes-sigs/krew/releases/latest/download/${KREW}.tar.gz" &&
tar zxvf "${KREW}.tar.gz" &&
./"${KREW}" install krew
)根据提示再配置一下环境变量,然后按照 sniff
kubectl krew install sniff参考资料:
eldadru/ksniff: Kubectl plugin to ease sniffing on kubernetes pods using tcpdump and wireshark (github.com)
一文读懂网络报文分析神器 Tshark: 100+ 张图、100+ 个示例轻松掌握 - 腾讯云开发者社区 - 腾讯云 (tencent.com)
重定向 Kubernetes pod 中的 tcpdump 输出 - charlieroro - 博客园 (cnblogs.com)